

人工知能による俳句の自動生成に関する実証実験「AI一茶くん」プロジェクト
以下のレポートは、Sapporo AI Lab事務局から一般財団法人さっぽろ産業振興財団へ提出された報告書を基に作成しております。
1.概要
1.1.目的
2017年9月にスタートした本実証実験は、AIが最も不得意とされている「感性」や「独創性」の結実した『俳句づくり』に挑戦し、AI文書作成の先進的技術開発に貢献することに加え、人工知能システムとしての機能実証を目的に、風景画像から俳句を自動生成する人工知能システムを開発し実証するものです。
学術的にも、深層学習を用いて風景・情景と言語情報を相互変換するためのマルチモーダルなニューラルネットワークの研究を通じて、俳句を理解するAIという観点から、知能とは何か、人と機械のコミュニケーションはどうあるべきかについて理解を深めることに貢献するものと考えます。
1.2.内容
(1)既存の俳句と適切な風景画像の組み合わせをタグ付けしたデータセットを作成し、その組み合わせを機械学習した人工知能ソフトウェアを構築すること。
(2)構築した人工知能は、任意の風景画像を入力として、新規に生成した俳句の文字列を出力すること。
(3)No Maps Trade Showなど展示会等のイベントにて、上記人工知能のデモンストレーション実施を含む、展示・社会実装への協力を行うこと。
1.3.実証体制
- 総括と機械学習モデル構築:株式会社テクノフェイス
- 俳句と画像のタグ付けツール開発:株式会社テクノフェイス
- 俳句と画像のタグ付け作業:株式会社調和技研
- 機械学習モデル構築:北海道大学調和系研究室
- デモンストレーションシステムのデザインとシステム構築:株式会社ワンズファーム
1.4.実証実施方針
本実験においては、人間が句会において写真を題材に俳句を詠むように、コンピュータが「画像データを基に俳句文字列を生成する」という機能を実現するために、以下のような作業ステップを踏むこととしました。
①画像データと俳句そのものや季語の文字列との関係性を数多く収集したデータベースを作成する。
②古典俳句の文字列データを機械学習して、俳句のルールに従う文字列を生成するソフトウェアシステムを作成する。
③画像データを指定するとそれに想起されたように見える俳句の文字列を出力するデモンストレーションシステムを作成し、展示会等にて公開する。
2.必要なデータ収集の方法と、俳句と画像のタグ付けツール開発
本実験では目的達成のため、以下の3種類のデータを収集することを試みました。
- 学習の教師となる、評価の高い俳句データ
- 俳句として必ず文字列に含まれるべき季語のリストデータ
- 俳句と画像の関係性を表現したマッチングデータ
以下、それぞれの収集方法について説明します。
2.1.俳句データ
俳句を学習する際に使用する文字列データを収集します。データに含む俳人は多作であり、情景を分かりやすく俳句にしているとされる小林一茶、正岡子規、高浜虚子の3人を想定しました。古典俳句に統一することで、学習の際の表現が現代俳句との間で揺らぐことを抑制すると考え、また、著作権等の議論を回避することも選択時の要素に組み入れました。
古典俳句のデータは、web上に公開されているいくつかのデータベース(OPEN Hammerhead一茶の俳句データベース(一茶俳句全集V1.30)、松山市立子規念博物館正岡子規俳句・松山市・CC BY 4.0、俳句例句データベース)から、スクレイピングしました。5-7-5音を認識するため、それぞれの俳句のひらがなでの読み方のデータもあわせて収集し、読みがついていない句にも手動で俳句の読みを付加しました。
機械学習にあたっては、表現が多様になることで学習効率が落ちることを避けるため、17音であること、季語がひとつ含まれること、文字列内に「(」等の記号を含まないこと、という条件をつけ、これに当てはまらない文字列は学習データとして不適として除外しました。この結果、最終的には計38,506句を収集し、これを俳句の教師データとしました。
2.2.季語データ
生成した俳句の正当性を判断するための条件のひとつとして利用するため、文字列に季語が含まれるかどうかを判定にする際に使用するデータを、web上のデータベース(現代俳句データベース)からスクレイピングして収集しました。季語には、「傍題」という、その季語を言い換えた別の季語が存在しているため、これも合わせて収集し、これら季語の読みを添えてデータベース化しました。最終的には8,665種の季語を収集しました。
2.3.俳句と画像のマッチングデータ
後述する俳句の生成プロセスにおいて、俳句と画像との適合度を学習する際に使用するデータを収集します。俳句と画像を1組として扱うデータとして設計し、このデータで使用する俳句は前述の俳句データで収集したデータベースを使用します。画像データは、(株)イメージナビ社の協力をいただき、画像素材販売サイトである「imagenavi」の画像を利用しました。次節で説明するWebツールを公開して、人間の目による俳句と画像のマッチングを行うために、ボランティアやアルバイトの募集も行い、手動でのマッチングデータ作成を行いました。データ数を補完するために、「imagenavi」のシステムで検索のためのアノテーションに、俳句データベースの俳句の季語と、季語データベース内の単語と一致するタグが入っていた場合には、その画像と俳句を1組のデータとして追加することとしました。その結果、現時点で369,754組のマッチングデータを収集しました。データ数は多いほど精度に貢献するため、Webツールは引き続き公開し、今後も収集を行ってまいります。
2.4.データの収集
俳句と画像のマッチングデータの収集は、以下のような専用のWebツール(http://haiku.s-ail.org/)を開発し、操作することで行いました。
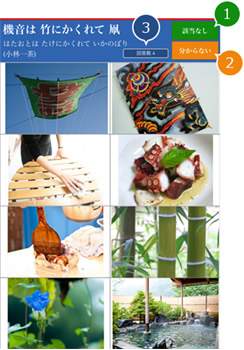
図:表示された俳句に適合すると思う画像をクリックするだけで、マッチングデータの収集が進捗するように、簡易な操作画面とした。俳句に適する画像がない場合は①をタップし、作業者が俳句の内容を理解できない場合は②こちらをタップするように案内しています。個別の作業状況を把握し、回答データを作業者をまたがって平準化するために簡易的なログインを促し、作業者にはこれまでにマッチング作業した回数が表示されることで、モチベーションを喚起します。
3.機械学習モデル構築
3.1.機械学習モデル構築とその方法
機械学習モデルの構築にあたっては、写真画像から俳句を詠むAIを開発するために、北海道大学と、株式会社テクノフェイスを中心とした企業の研究チームにおいて、いくつかの手法を試行しました。いずれの手法においても、具体的には、再帰的な深層学習のモデルを採用して、俳句をデジタルな文字列として学習し、先行する文字や単語に続く文字や単語を予測して出力することで、確率的に「俳句らしさ」の高い文字列を生成します。画像の認識は、既に世界的に実績を上げている畳み込み型の深層学習データも活用しながら、認識結果を俳句生成結果に反映することを試みます。以下では、北大研究チームの試行した「AI一茶くん(ちび)」ならびに「AI一茶くん(成長版)」、企業研究チームの試行した「漢詩モデル」についてそれぞれ簡潔に解説します。
3.2.北海道大学調和系研究室によるモデル構築(AI一茶くん(ちび)における俳句の機械学習の手法)
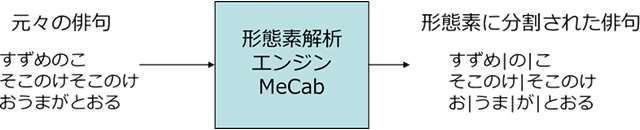
北大の研究チームが主体でまず取り組んだ「AI一茶くん(ちび)」の中核アイディアは、確実に5-7-5音を形成するために音数を計測可能なひらがなの俳句データで学習・生成を行うことにあります。全体の流れとしては、約2万の小林一茶のひらがなの俳句文字列を形態素解析エンジンMeCabによって形態素に分け、形態素に分けられた俳句をRecurrent Neural Network(RNN)に入力し、文脈から次にどの形態素が出現するかを学習します。

3.2.1.学習の過程
学習処理1:俳句の形態素分割
学習元となる俳句をMeCabに入力して形態素に分割します。
学習処理2:形態素へのID割当
新しく出現した形態素から順に形態素リストに格納し、番号を付与します。

学習処理3:形態素に分割された俳句をIDに変換
形態素リストを参照し、IDに変換します。

学習処理4:RNNでの学習
IDそれぞれをワンホットベクトルに変換したものをRNNに入力し、文脈から次に出現するID(形態素)の確率を学習します

3.2.2.俳句の出力の手法
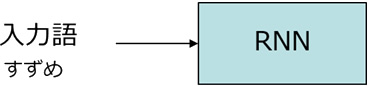
機械学習処理が完了したら、学習済みのRNNから俳句となる文字列を出力します。
出力処理1:先頭単語の入力
出力処理2:次に来る単語の確率のランキングを出し、五または七音を超えないように次の単語を選択します。
(例)「すずめ」の入力とした場合の次の単語のランキング
うすい 0.00133372
ひねくれ 0.00112486
じじい 0.00109285
てきぱき 0.000917972
やぶれ 0.000908962
ちょうりょう 0.000907676
ぎに 0.00085987 ← 上の句なら五音を超えないこの単語が選ばれます
出力処理3:五または七音に満たないなら処理2を繰り返します。
【出力例】入力は先頭の形態素です。

3.2.3.画像との連携
後述するNoMaps2017でのデモンストレーションをスケジュール上の目的とした「AI一茶くん(ちび)」の段階では、画像認識のAIとの連携までは完成していないため、いくつかの画像ファイルにそれぞれ象徴的な単語(雪景色の写真に対して「ゆき」など)をひとつタグとして付与し、そのタグ文字列を俳句生成の入力としました。
3.2.4.生成俳句の評価について
後述するNoMaps2017でのデモンストレーションシステムでは、展示会場や新聞、TVといった多くのメディアにおいて多くの人々の目に触れる機会がありましたが、俳句そのものの「出来」の評価についてはまだ低く、ひらがなで出力される文字列は5-7-5音の形態をとっているものの、俳句の情景はおろか、意味を形成しているとは言い難く、情報科学的に興味を惹く成果ではあるものの、俳句を知る一般の方々の納得を得る俳句を詠むまでには至らない結果となりました。
3.3.AI一茶くん(成長版)における俳句の機械学習の手法
「AI一茶くん(ちび)」の成果から、ひらがなでの形態素解析による意味確定のあいまいさなどが主原因となって、ひらがなでの学習では全体として日本語の意味形成ができないと考え、別途日本語での文章生成に成果を挙げている、「漢字交じり文の一文字単位での学習」モデルを試行することとしました。

3.3.1.俳句データの学習過程
次期モデルでは、文章生成において成果を上げているLSTM(Sundermeyer, Martin, Ralf Schlter, and Hermann Ney. ”LSTM neural networks for language modeling.” Thirteenth Annual Conference of the International Speech Communication Association. 2012.)という深層学習のモデルを使用して俳句の生成を試みました。
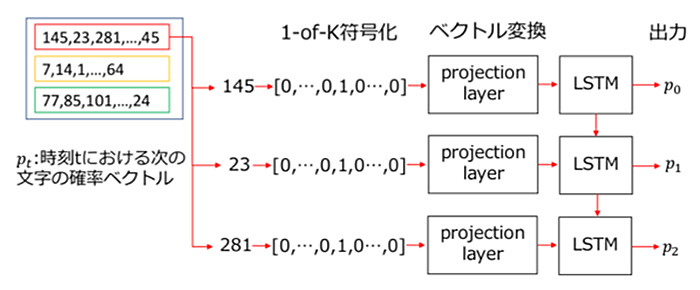
「ちび」と同様に文字列を数値ベクトル化してニューラルネットワークに入力します。具体的には、学習データに使用された文字を出現順に若い番号からIDを与え、学習データの文字をそれぞれのIDに変換してバッチに分けます。バッチ内のサンプルは予め設定したBack Propagation Through Timeの長さ分の数字の列となり、改行文字にあたるIDごとにサンプルを区切ることはしません。1-of-K符号化したサンプルを先頭から順にprojection layerに入力してベクトルに変換し、LSTMに入力します。
LSTMの出力は次に出現する文字の確率であり、正解データは次の文字のID番目が1のワンホットベクトルとなります。サンプルを最後まで入力し終えた段階でLSTMの状態をリセットし、誤差を計算します。
パラメータを以下のように設定して学習を行いました。LSTMユニット数は全てのLSTM層で共通としました。実装には、Google提供のオープンソース深層学習フレームワークTensorFlowを利用しました。
- LSTM層数:3
- LSTMユニット数:1024
- 最適化手法:Adam16)
- 学習率:0.02
- 減衰率:0.02
- エポック数:300
- バッチ数:50
- サンプル長:100
- 目的関数:クロスエントロピー
3.3.2.俳句の出力
俳句の出力にあたっては、学習したLSTMで文字列を出力する際、引き金となる最初の入力を改行文字とし、次の文字の確率を計算してルーレット選択をして、選ばれた文字が次の入力となります。改行文字が出現してから次の改行文字が出現するまでに選択された文字列が出力俳句の候補となります。ここでは、連続的に無限に文字列が生成されるため、改行文字が指定した回数出現したことを条件に出力を停止することとしました。

図:漢字交じり文字列で学習したLSTMの出力例
3.3.3俳句フィルタ
俳句生成部は大量の文字列を短時間で出力しますが、その文字列は必ずしも俳句としての条件やルールを満たしていない文字列を含んでいるため、俳句として体を成す最低限かつプログラム記述が可能な条件を設定して、「俳句フィルタ」としてプログラムを作成し、出力文字列のうち条件を満たしている文字列のみを抽出することを試みました。ここで定義した俳句としての条件とは、以下のとおりです。
①17音(5-7-5)になっている
②季語を1つ含む
③切れ字(や/也、かな/哉、けり)を1つ以下含む
④既存(学習元データ)の俳句と類似していない
これらの条件を満たしてない句も俳句として認められる場合も多く存在しますが、判定の幅が大きくなりすぎ、プログラムでの処理に向かないため、本実験ではこれらの条件を満たす句のみを選定することとしました。作成した俳句フィルタプログラムは生成された文字列に対して以上の条件を満たしているかをそれぞれ判定するものです。以下にそれぞれの判定方法を説明します。全ての判定をクリアしたものを最終候補作品として出力します。
①音数判定
音数判定には、漢字交じりとひらがなで構成された俳句文字列のデータから、漢字とその読み方のすべての例の辞書を作成します。俳句では漢字の読み方に複数あることを利用して音数を整えることをします。そのため、音数を正しく測るために読み方のバリエーションのデータを準備します。フィルタプログラムでは、生成された文字列に使用されている全ての漢字の読みを、作成した読みがな辞書から組み合わせを探索し、17音となる読みの候補が見つかったところで音数判定は成功とみなします。
5-7-5の判定には、17音となる読み方で6音目と13音目に漢字の読みに含まれる文字とその漢字の送り仮名がないことで判断します。
②季語判定
2.2節で作成した季語の辞書から季語を1つずつ抽出し、生成された文字列にその季語が含まれているかを判定します。含まれている季語が1つのみの場合、季語判定フィルタは成功と判断します。
③切れ字判定
生成文字列を音数判定した際のひらがな読みの文字列を5音、7音、5音に分け、それぞれの文字列が「や」「かな」「けり」「なり」で終了している場合、切れ字が入っていると判定します。切れ字で終了している文字列が1つ以下の場合に切れ字判定は成功とします。
④類似度判定
既存の俳句(学習に使用した俳句データ)に似すぎていないかを見分ける類似度判定には、レーベンシュタイン距離(編集距離)を使用します。生成した俳句を学習データとのレーベンシュタイン距離をそれぞれ計算し、最小値が4以上なら類似度判定は成功としました。
3.3.4.俳句とモチーフ画像の適合判定
俳句フィルタを通して「正しい」俳句と判定された文字列とモチーフ(お題)画像の適合度を計算し、適合度が高いほどその俳句をモチーフ画像に基づいて生成した俳句ととらえることで、画像と俳句の連携を実現します。
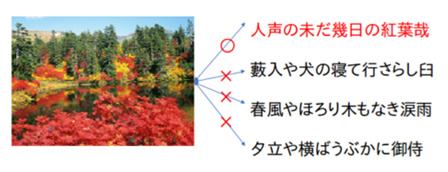
図7 適合判定概要
事前準備として、学習データの俳句に使用されている漢字それぞれに出現順に若い番号からIDを付与します。適合判定では2.3節で作成した画像と俳句の組のデータを正の学習データとして使用し、負例として同数の画像と俳句の実在しない組を学習データと同数だけランダムに生成します。まず学習データの画像から、Google社で公開している深層学習画像認識モデルであるInception-v3を使用して特徴量ベクトルを得ます。次に学習データの俳句に使用されている漢字の使用回数を数え、その漢字のID番目の要素が使用回数となるベクトルを計算します。ここまでで得られた2つのベクトルを結合して入力ベクトルとします。適合判定では、全結合層のニューラルネットワークに入力し、入力された組が正の学習データに含まれているマッチングデータかどうかで評価判定するものとします。学習パラメータは以下のように設定しました。
- 中間層:1024,512,256
- 最適化手法:Adam
- 学習率:0.00001
- エポック数:1000
- 目的関数:クロスエントロピー
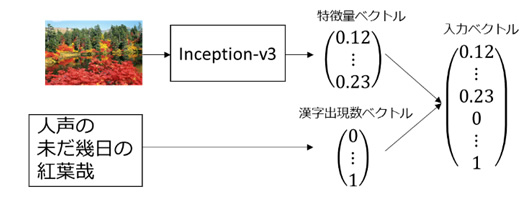
図8 画像とのマッチング学習
3.4.株式会社テクノフェイスによるバックアップアプローチ
深層学習を利用した研究開発においては、データセットと機能の仮説に対して、期待した性能が発揮されることを保障することが困難であり、AI俳句についても前例のない試みであることから、北海道大学川村研究室の提案する3.3節で説明したモデルのほかに、株式会社テクノフェイスを中心とした企業チームでは、北大モデルのいくつかの課題を回避することを目的として、北大チームと同じ俳句、季語、画像のデータセットを利用して機械学習する以下のモデルを提案しました。
3.4.1.俳句の学習と生成
北大モデルは一般的に英語圏で成果の上がっている、画像から説明文章を生成するモデルに基づいたものですが、課題として、画像データと俳句出力の相関判定を画像認識の特徴ベクトルに依存することになるため、出力の性能調整をする際に、画像認識に問題があるのか、俳句の学習に問題があるのか判断しづらい点にあると考えました。そこで、画像認識の出力と、俳句生成の入力情報に可読性の高いデータを仲介させることにより、画像認識と自然言語学習の問題を切り分けることを可能にすることを試行します。
具体的には、俳句の学習モデルにSeq2Seqと呼ばれる、英語→日本語など機械翻訳に利用される構造を採用します。ここで翻訳するのは、季語やお題など、俳句に関連するキーワード群(A,B,C)を、俳句の文字列(W,X,Y,Z)に変換することを試みます。学習には、2.1節で準備したデータのそれぞれの俳句内に出現する名詞句を並べて入力キーワードとし、俳句そのものを出力として学習します。
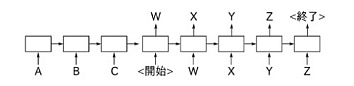
図:Seq2Se2による学習データ
3.4.2俳句の出力
学習の完了したSeq2Seq学習器に対して、出力したい俳句に関連する名詞の組合せを入力することで、新規の俳句を生成することを試みます。北大モデルでは連続する俳句そのものを学習したため、出力時に連続して生成される俳句に関連性はありませんが、生成したい俳句の関連キーワードを入力とすることで、ある程度俳句の内容のターゲットを絞り込むことができると考えます。
しかしながら、出力文字列の一般的な俳句としての完成度を評価する指標がないため、本モデルにおいても確率変数を変化させながら多くの候補文字列を出力させ、3.3.3の俳句フィルタによって候補を絞り込む処理を行っています。
3.4.3.画像の認識とキーワード生成
画像認識には、北大チームでも利用したInception-v3をベースとして、イメージナビ社の風景画像とアノテーションセットを追学習させています。これにより、俳句のお題となる画像に対して可読性のあるキーワードセットとして俳句出力のトリガーを入力することができます。
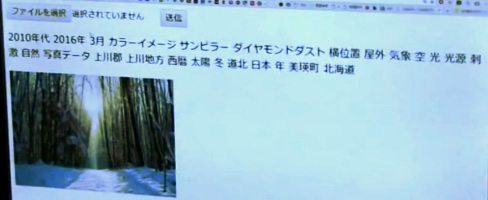
図:風景画像に対して画像認識して出力されるキーワードの例
Seq2Seqに入力されるキーワードとして、これら単純な画像認識結果の文字列を入力したのでは、俳句として発想が乏しくなることが予想されるため、これらのキーワードをさらにWikipedia等のインターネット上のコンテンツから類義語の置き換え、事件や関係事象で想起される単語など、キーワードを飛躍させる必要があると考えています。これらの実装については今後の研究課題と考えています。
3.5.北海道大学調和系研究室モデルと株式会社テクノフェイスモデルの相違についての概要
3.3節ならびに3.4節で説明した画像から俳句を生成する二つのモデルについて、以下の図にまとめます。学習フェーズでは、それぞれ、画像と俳句、画像と単語の組合せを学習する画像認識モデルを採用しています。俳句の学習には、連続した俳句文字列の学習と、単語と俳句の組合せを学習するモデルを採用している点に差異があります。
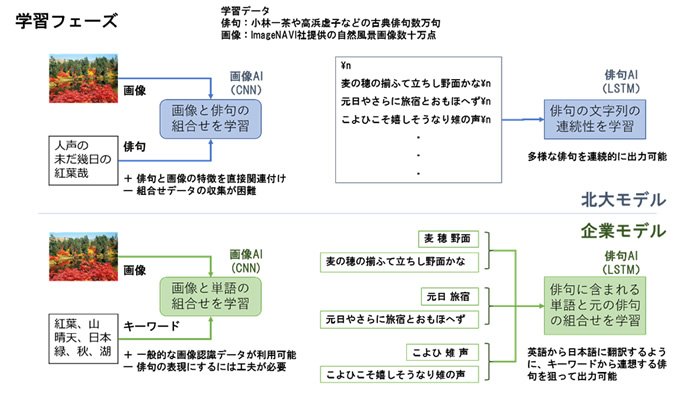
図:学習フェーズの考え方の対比
出力フェーズでは、北大モデルが連続した俳句出力から、画像適合度を判定する方式なのに対し、企業モデルでは、画像認識結果のキーワードを、俳句への翻訳の入力として扱う点が大きく異なります。
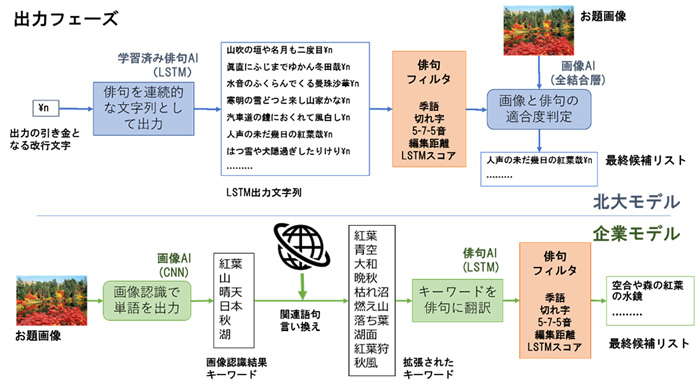
図:出力フェーズの考え方の対比
3.6.残された研究課題について
北大、企業のいずれの方式で生成された俳句についても、最低限の俳句のルールによりフィルタリングしたのち、イベント等ではフィルタ後の候補から、人間が判断して最終的な一句を提示しています。大量に出力された俳句の体裁をとった文字列の、俳句としての良し悪しを評価する方法については、俳句の世界においてどんな句であれば評価が高いのか、「良い」句を生み出すテクニックを機械学習することは可能なのか、情景を想起させる言葉選びとはどういうものなのかなど、非常に難しい課題もあり、今後も継続的に深く研究することが必要です。
「AI一茶くん」の公開事例
■2017年
NoMaps2017においては、AI一茶くん(ちび)を、お披露目しました。

図:デモンストレーションブース会場にて、秋元札幌市長の視察を受ける

図:開発チームによる座談会イベントの様子
(左:北大川村教授、中央:テクノフェイス石田、右:北大伊藤準教授)
■2018年
NHK「超絶 凄ワザ!」への出演
これまでのメディア露出を受け、NHK名古屋局より、同社番組「超絶 凄ワザ!」への出演オファーを受けました。番組では、3.3節ならびに3.4節での俳句生成モデルでの出力俳句と、人間の俳人の対決を行うことになり、指定されたお題画像に対してAIが生成した俳句と、俳句甲子園チャンピオンや、俳句の聖地松山の俳人集団、また有名芸人の詠んだ俳句について、著名な俳人が客観的に良し悪しを判定するという演出が企画されています。同時に、難航していた画像と俳句のマッチングデータの収集ボランティア募集の告知もNHKの協力により、全国に向けて行われました。
札幌でのロケハン撮影ならびに、平成30年1月12日の名古屋でのスタジオ収録を行い、2月26日に全国放送されることとなりました。放映のニュースか多くのWebメディア等でも取り上げられ、本業務の成果を広く全国にPRする貴重な機会を得ることができました。
■2018年
NoMaps2018においては、季語の音声入力で俳句を生成する「AI一茶くん」を展示しました。


